
Suite au script de la séance précédente ci-dessous :
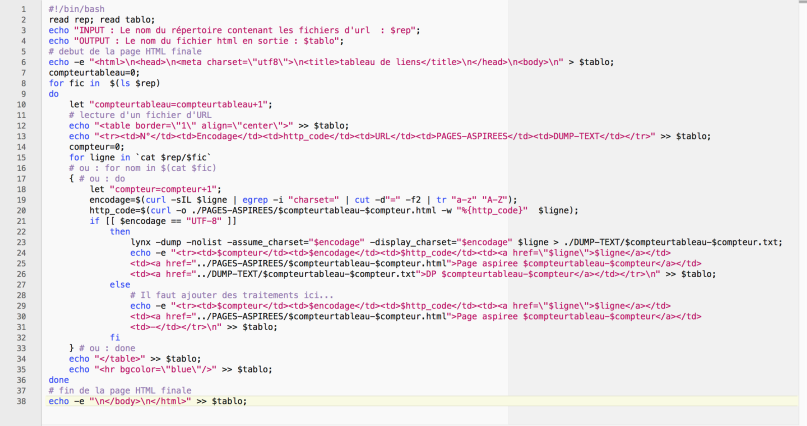
Ce qu’on a fait jusque là :
- Lire les donées en entrée (x fichiers d’URLs
- Ecrire dans un fichier de sortie en HTML (tableaux)
- et pour chacun des fichiers d’URLs…
- Détecter l’encodage des données(de l’URL)
- Récupérer l’URL localement sur ma machine
- Si l’encodage est UTF8
- ALORS : extraction du texte « brut » de la page
- AUTREMENT : rien pour le moment
- Ecrire les résultats dans un tableau HTML (pour accéder aux données traitées et aux contenus textuels)
Alors, pour enrichir le script précédent, les problèmes à résoudre sont :
- S’assurer que la récupération d’une URL se passe bien
- Transcoder les données non UTF-8 : ici, introduire la commande iconv
- Extraire des contextes des unités lexicales choisies : introduire la commande egrep
- Ecrire tous les résultats dans le tableau final : insérer les colonnes idoines
après la détection de l’encodage de la page en ligne, pour transcoder les données non UTF-8,

Finalement, le script du résultat de cette séance est …

